
SysY to LLVM简易编译器文档
1.编译器简介
(1) 简介
该编译器通过Java语言,实现了词法分析,语法分析,符号表管理与错误处理,llvm代码生成功能,将输入的简化的符合SysY语法的代码转换为LLVM语言。
具体语法见文法定义及相关说明
(2) 错误处理
本编译器共可处理10种错误具体如下:
| 错误类型 | 错误代码 | 解释 |
|---|---|---|
| 非法符号 | a | 格式字符串中出现非法字符,如&等,报错行号为 |
| 名字重定义 | b | 函数名或者变量名在当前作用域下重复定义 |
| 未定义的名字 | c | 使用了未定义的标识符报错行号为 |
| 函数参数个数不匹配 | d | 函数调用语句中,参数个数与函数定义中的参数个数不匹配 |
| 函数参数类型不匹配 | e | 函数调用语句中,参数类型与函数定义中对应位置的参数类型不匹配 |
| 无返回值的函数存在不匹配的return语句 | f | 报错行号为‘return’所在行号 |
| 有返回值的函数缺少return语句 | g | 只需要考虑函数末尾是否存在return语句,无需考虑数据流 |
| 不能改变常量的值 | h | |
| 缺少分号 | i | 报错行号为分号前一个非终结符所在行号 |
| 缺少右小括号 | j | 报错行号为右小括号前一个非终结符所在行号 |
| 缺少右中括号 | k | 报错行号为右中括号前一个非终结符所在行号 |
| printf中格式字符与表达式个数不匹配 | l | 报错行号为‘printf’所在行号 |
| 在非循环块中使用break和 continue语句 | m | 报错行号为‘break’与’continue’所在行号 |
(3) 生成结果展示
输入代码
1 | int main(){ |
输出
1 | declare i32 @getint() |
2.编译器的总体设计
(1) 总体结构
程序总体架构如图:
程序运行后通过词法分析生成WordList, 输入到语法分析中生成Ast(抽象语法树),将Ast输入到错误处理部分中构建符号表,进行错误处理,无错误的抽象语法树会传入到代码生成部分生成LLVM代码,若存在错误则输出错误后程序结束,所有模块皆可通过调用Writer模块输出本模块的处理结果
- Writer:将结果输出到对应文件
- 词法分析:遍历按行读入testfile.txt中源程序,经过词法分析得到WordList
- 语法分析:遍历WordList递归下降生成抽象语法树
- 错误处理:遍历抽象语法树,构建符号表进行错误处理
- 代码生成:遍历抽象语法树,生成LLVM代码
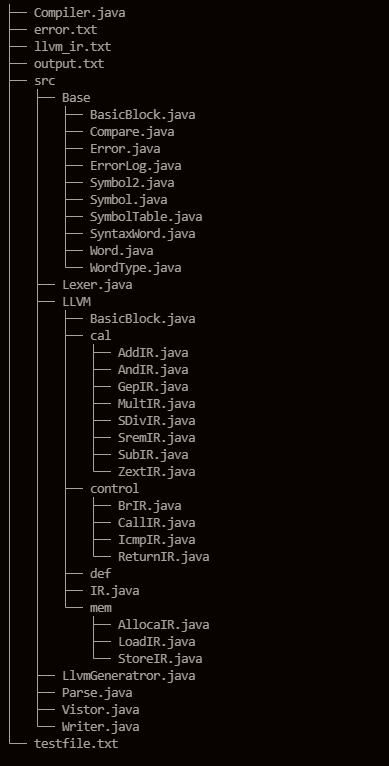
(2) 接口设计
项目文件组成和类与接口示意图如下:
- Compiler:程序入口
- Writer:文件写入模块,用于输出各模块处理结果
- Lexer:词法分析模块
- Parse:语法分析模块
- Vistor:错误处理模块
- Llvmgenerator:代码生成模块
- 词法分析相关类:
- Word:单词类,含该词的类别,内容,行号字段
- WordType:枚举类,枚举单词类别
- 语法分析相关类:
- SyntaxWord:抽象语法树节点,用于构建抽象语法树
- 错误处理相关类:
- error:错误类,包含行号,错误类型字段
- ErrorLog:错误输出单例,内含ArrayList
,用于储存所有错误,及用于错误输出的接口 - Symbol:符号类,内含构建符号表所需字段
- SymbolTable:符号表类
- 代码生成相关:
- Symbol2:代码生成所使用的符号类,内含用于代码生成的符号信息
- AddIR,MultIR···ZextIR:计算相关的llvmIR类,用于输出对应LLVM语句
- BrIR,CallIR,IcmpIR,ReturnIR:跳转相关的llvmIR类,用于输出对应LLVM语句
- AllocaIR,LoadIR,StoreIR:存储相关的llvmIR类,用于输出对应LLVM语句
(3) 文件组织
程序文件结构如下:
- Compiler.java:程序入口
- testfile.txt:待编译的源程序
- output.txt:语法分析结果
- error.txt:错误信息
- llvm_ir.txt:llvm代码输出
3.词法分析设计
编码前设计
编码前设计Lexer模块逻辑如下:
由Compiler模块持续按行读入文件,将读入行内容和行号传入Lexer模块,Lexer模块循环读入单个字符进行处理

编码后修改
对于各类符号单词,原本设计存入HashMap中,传入该分支后用if else 进行分类处理,后改为使用LinkedHashMap,在处理完其他情况后使用for循环遍历处理,缩短了代码行数,提高了代码的简洁性。
对于注释的处理原本设计使用预读,逻辑为对读取到的’/‘的后继符号进行判断,若存在’/‘则为单行注释,存在’*‘为多行注释,其他情况则当前’/‘当做除号处理,回退读指针,编码完成后多次测试发现存在bug,未考虑到’/'为该行末尾符号,无后继符号,应当作为除号处理,后添加对行末符号的判断处理逻辑。
4.语法分析设计
编码前设计
向Parse模块中传入Lexer模块生成的WordList,遍历该列表的单词,递归下降处理各语法成分,对于含有左递归的文法,如AddExp,LOrExp等,为解决回溯问题使用预读进行处理。
编码后修改
1.左递归文法
对于处理左递归的方式,实际选用如下方式处理。
1 | private SyntaxWord AddExp() { |
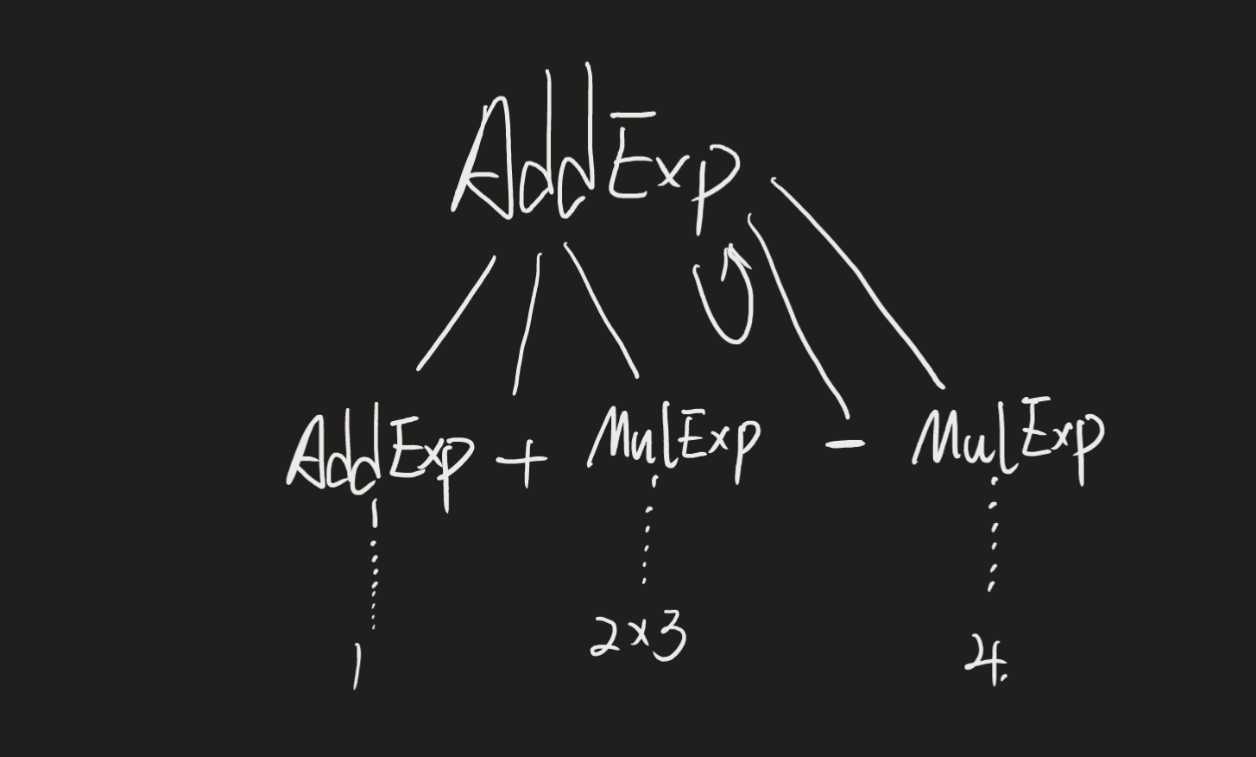
对于需要处理的AddExp,当前单词直接当做MulExp处理,添加到当前AddExp的子节点中,若该单词后继为’+‘||’-',则为当前的AddExp(含一MulExp的子节点)创建一个AddExp的父节点Father,为运算符号创建节点,添加仅Father,将后继单词作为MulExp处理,添加仅Father节点,最后返回Father节点。显然
Father节点只在while循环外创建了一次,由于Father.addChild(addExp);addExp = Father;,当循环第二次运行时,Father节点与addExp节点是相同的,导致addExp中一子节点会指向自己,导致在遍历语法树的时候死循环,且由于在语法分析部分,处理结果都是在递归下降过程中添加字符串到res数组中,最后遍历输出数组产生,而不是由遍历抽象语法树生成,导致此Bug没有被发现,且由于Father节点在while循环之外被创建,对于例如1+1的输入可以生成期望的抽象语法树,但对于多层AddExp嵌套,如输入2+3-4+5会生成错误的语法树。错误情况: AddExp的Child中存在自身,遍历树的时候产生死循环
后修复为如下代码,在
while循环中新建Father对象,使得多次循环中Father改变,不会导致addExp的child中有指向自己的变量。其余含左递归的文法皆做相同处理修复BUG。

1 | private SyntaxWord AddExp() { |
2.Stmt处理
在处理Stmt的
[Exp];和LVal = Exp;情况时,由于LVal和Exp的First集都含有Ident,对判断逻辑的编码产生了很大阻碍,最后采取对读取到的Ident记录其下标,并都按照LVal处理建立对应节点,当为[Exp];情况时则不将LVal节点加入Stmt的子节点中,同时调用back函数清除添加到res数组中的错误字符串,在back函数编写过程中,起先未考虑到LVal可能由多个终结符构成,即LVal为数组时,Ident后续的单词也会被加入LVal的子节点中,这些结果也是错误的需要回退,最终修改为如下代码,正确处理了Stmt节点,解决了back函数的BUG。
1 | else if (symTpyeCheck(sym, WordType.IDENFR)) { |
5.错误处理设计
编码前设计
经对所有错误类型分析,做出如下分配,a类错误在Lexer模块中处理,i,j,k类错误在Parse模块中处理,其余在错误在模块Vistor中处理。分析发现构建符号表仅需要对抽象语法树中
FuncDef、Block、VarDef、MainFuncDef、LVal、Stmt、ConstDef、UnaryExp节点进行处理则设计编写traverseTree函数对抽象语法树前序遍历,handle函数使用if else对节点进行分类处理。设计符号类如下:
1 | public class Symbol { |
对于符号表,使用
HashMap<Interger, SymbolTable> floor_symbolTable存储符号表类,floor对程序层级进行计数,处理到Block则floor++,处理完毕后floor--, 对于函数,使用HashMap<String, Symbol> funcName2Symbol存储函数名对应的符号表,HashMap<String, Table> funcName2parTable存储函数名对应的参数符号表。
编码后修改
1.符号表实现
实际编码中对符号表结构做出修改,不使用预先设计的
HashMap<Interger, SymbolTable> floor_symbolTable存储符号表实现符号表嵌套关系,而是在符号表类中添加其父符号表指针,使用全局变量curTable指向当前处理的符号表,globelTable指向最顶级的符号表,符号表类设计如下:
1 | public class SymbolTable { |
for循环语句处理
在编码中对于
Stmt -> 'for' '(' [ForStmt] ';' [Cond] ';' [forStmt] ')' Stmt情况中最后的Stmt节点直接默认其为Stmt -> Block情况,未考虑如下情况且通过了错误处理测试,导致后续开启错误处理代码生成时产生BUG。
1 | //for语句后非Block情况 |
对于上述BUG,显然创建新的Block节点加入终结符节点
LBRACE,非终结符节点BlockItem及终结符节点RBRACE,将for末尾的Stmt节点从取出添加到新建的BlockItem节点并从父级Stmt节点删除,向父级Stmt节点添加Block节点对程序的运行结果是没有影响的,因此后续添加在处理逻辑中添加了wrapWithBlock函数向其中传入Stmt节点返回用Block包装后的Block节点,对for语句末尾Stmt的类型判断,若为非Block情况则调用wrapWithBlock函数包装后处理。
1 | private void Stmt(SyntaxWord syntaxWord) { |
6.代码生成设计
编码前设计
代码生成选择LLVM IR作为目标代码,设计参考课程网站上的LLVM指导手册。由于用于错误处理的SymbolTable类无法从父级表获得子表,设计用于代码生成的Symbol类如下,同时原抽象语法树节点类添加若干字段。利用LLVM编译时的特性,设计基本块命名为
"block" + blockId,即字符串+数字形式,这样在编译时编译器会自动为块重新标号,这样在输出目标代码时可以不用保证块号递增,大大减轻对基本块标号的工作量,例如生成如下目标代码, 其块号不是单调递增的,通过LLVM编译后可正确运行。
1 | block3: |
Symbol类:
1 | public class Symbol2 { |
SyntaxWord类:
1 | public class SyntaxWord { |
继续使用递归下降遍历抽象语法树,处理各个节点,设计
handle函数将输入入节点传入对应函数处理,其中LOrExp与LAndExp传入对应函数前记录该节点为顶级父节点,用于实现短路求职。
1 | private void handle(SyntaxWord node){ |
对于目标代码设计继承IR接口的各语句类如下:
重写各类
toString方法用于生成对应语句
例:

1 | public class MultIR implements IR { |
对于仅运算符不同的IR语句设计
calIR函数区分对应语句
1 | private String calIR(String leftValue, String op, String rightValue) { |
符号表部分使用栈式符号表,全局变量表,函数表是哪个表实现
1 | HashMap<String, SyntaxWord> global; |
可知代码生成时AddExp与MulExp唯一区别在于中间的运算符号不同,故合并到MulExp中处理,同时一些常数可以直接计算出值在进行代码生成,设计该节点及其子节点是否全为常数的判断逻辑,调用
calculateNum函数计算该值。
1 | private void AddExp(SyntaxWord node) { |
短路求值,首先对于LAndExp的抽象语法树,当前节点子节点数为1时即该节点仅有1子节点EqExp,处理该EqExp,向上传值后结束,对于如图形式的抽象语法树,左杈LAnd节点继承其父节点的FalseId,递归处理左杈LAnd,处理完后创建新TrueBlock跳转到右杈EqExp块。当左杈LAnd节点的父节点为顶级LAnd节点时,顶级LAnd的TrueId,FalseId,StmtId同父级LOr节点,则在处理完最后的EqExp后续输出LOr节点对应LLVM IR语句。
LOrExp抽象语法树的处理基本同理,仅需注意左杈LOr节点要继承父节点TrueId新建FalseBlock跳转至右杈LAnd,当左杈LOr的父节点为顶级LOr节点时需要输出父级Cond节点对应LLVM IR语句

1 | private void LAndExp(SyntaxWord node) { |
LVal处理较为复杂,首先将LVal分为全局与局部,全局的变量可从
global表中获取,之后又分为全局变量赋值和全局变量使用,变量类型为普通变量,一维数组与二维数组,局部变量需按对应变量类型(普通变量,一维数组与二维数组)处理。LVal节点子节点数可能为1,4,7,size == 7时最为简单,仅为对二维数组具体元素的使用,当size == 4时可能为一维数组具体元素的使用或二维数组的部分(二维数组的部分传参)使用,当size == 1时,可能为普通变量使用或一维数组传参,或二维数组传参。
具体设计如下:
1 | private void LVal(SyntaxWord node) { |
编码后修改
基本同编码前设计,仅针对UnaryExp的遗漏情况进行修改,以及Parse模块添加语句减少代码生成工作量。
- 实际测试中发现UnaryExp与UnaryOp也存在递归情况,设计对UnaryExp的抽象语法树自底向上进行运算,先递归访问到最右端的UnaryExp,计算其初值,之后自底向上,遇到"+“则直接向上传值,”-"则新增sub语句,用0减去当前值实现取负后在向上传值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
ArrayList<SyntaxWord> children = node.getChildren();
// UnaryExp → PrimaryExp | Ident '(' [FuncRParams] ')'| UnaryOp UnaryExp
if(!children.get(0).isEnd() && children.get(0).getType().equals("PrimaryExp")){
SyntaxWord primaryExp = children.get(0);
handle(primaryExp);
node.setValue(primaryExp.getValue());
node.setRegId(primaryExp.getRegId());
node.setSymbol(primaryExp.getSymbol());
}
else if (!children.get(0).isEnd() && children.get(0).getType().equals("UnaryOp")) {
String unaryOp = children.get(0).getChild0Content();
SyntaxWord unaryExp = children.get(1);
handle(unaryExp);
switch (unaryOp){
case"+"-> node.setValue(unaryExp.getValue());
case "-"->{
if(floor == 0){
int preValue = Integer.parseInt(unaryExp.getValue());
preValue = -preValue;
node.setValue(String.valueOf(preValue));
}else{//添加Sub 0 语句
String left = "0";
String right = unaryExp.getValue();
writeRes(calIR(left, "-", right) + "\n");
String reg = "%x" + regId;
node.setRegId(reg);
node.setValue(reg);
++regId;
}
}
}
···
}
}
- 为减少代码冗余,减轻代码生成阶段工作量,在SynTaxWord类中新添一维数组
forElements及字符串’StmtType’,在Parse模块Stmt函数中将for语句的元素存在情况存于forElemets中,判断Stmt类型后将其类型储存在StmtType中以便LlvmGeneratror模块中直接使用switch分类处理。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
···
int[] forElemets = null;
//size = 3的一维数组以1,0标记该for语句是否有ForStmt,Cond和forStmt
//如for(i = 1;;); 其forElements为{1,0,0}
···
>}
>private void Stmt(SyntaxWord node) {
ArrayList<SyntaxWord> children = node.getChildren();
String stmtType = node.getStmtType();
switch (stmtType){
case "Assignment"->{
···
}
case "Block" ->{
···
}
case "Exp" ->{
···
}
case "Return"->{
···
}
case "Input"->{
···
}
case "Output"->{
···
}
case "If"->{
···
}
case "Break"->{
···
}
case "Continue"->{
···
}
case "Loop"->{
···
}
}
if(node.getStmtId() == -1){
return;
}
writeRes(tab + "br label %block" + node.getStmtId() + "\n");
}